Uber Eats Image Deduping & Storage Recap
· 2 min read

Precontext: Content Addressable Caching
- Content-addressable caching (or content-addressable storage + caching) is a technique where the content itself determines the key used to store and retrieve it.
- The core idea is Instead of identifying data by (URL, filename or ID) we use a hash of the content (like SHA-256, MD5, etc).
- So the address = hash(content).
Why?
- Uber Eats handles 100M+ images.
- Many merchants upload identical product images means big duplicate storage.
- Frequent updates can cause repeated downloads, processing, and CDN usage.
- Goal: reduce storage cost, processing load, and latency.
Idea: Content‑Addressable Storage
we built a deduplication layer based on image hashes.
Three Metadata Maps
- maps are usually caches but backed by DBs so survive restarts
- main image sources is S3 like blob storage of uber itself
| Map Name | Key | Value | Why |
|---|---|---|---|
| URL Map | Image URL | Hash of image | To avoid re-downloading the same external URL again; detects repeated URLs and checks whether the underlying image changed. |
| Original Image Map | Image Hash | Raw / original image | To deduplicate identical images uploaded via different URLs; many merchants may use same product image → only store one copy. |
| Processed Image Map | Image Hash + Processing Spec | Processed / resized image | To avoid re-processing the same image in different sizes/formats; store and reuse thumbnails, WebP versions, etc. |
Processing Flow
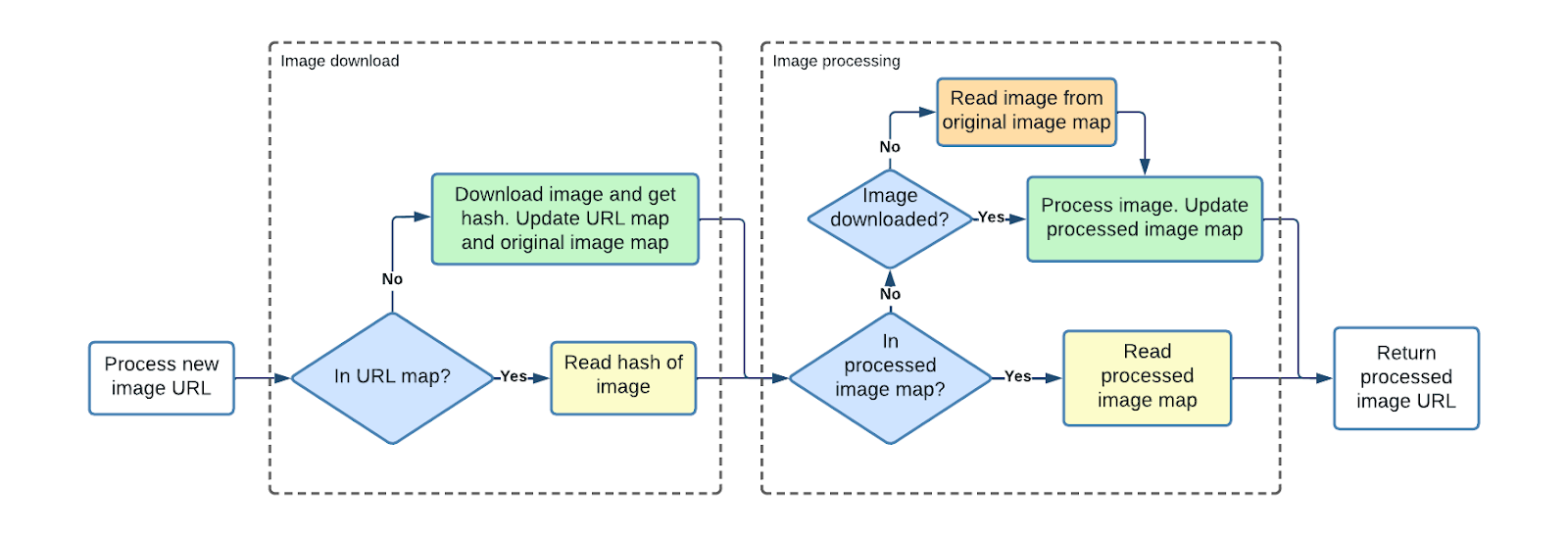
- Given (URL + processing spec), check URL map.
- If URL seen → get hash; else download → hash → store.
- Check Processed Image Map.
- If processed variant exists → return cached version.
- Else process → store → return.
Update Handling

- Uses HTTP Last-Modified header to detect changed images.
- If unchanged, skip re-download and reuse existing blobs.
Error Caching
- Processing errors (e.g., corrupt image, too small) are also cached.
- Prevents repeated unnecessary attempts.
Value
- Latency improved: P50 ~100ms, P90 ~500ms.
- less than 1% of weekly calls needed actual image processing.
- Huge savings in storage + CDN + CPU usage.
Key learnings
- Hash-based content-addressable storage eliminates duplication.
- Separate raw images from processed variants for flexibility.
- Use metadata maps for fast lookups.
- Cache both successes and failures.
- Use HTTP metadata to detect updates cheaply.