Availability and Consistency
Availability
Availability = Uptime / (Uptime + Downtime);
-
Uptime: The period during which the system is functional and accessible.
-
Downtime: The period during which the system is unavailable due to failures, maintenance, or other issues.
-
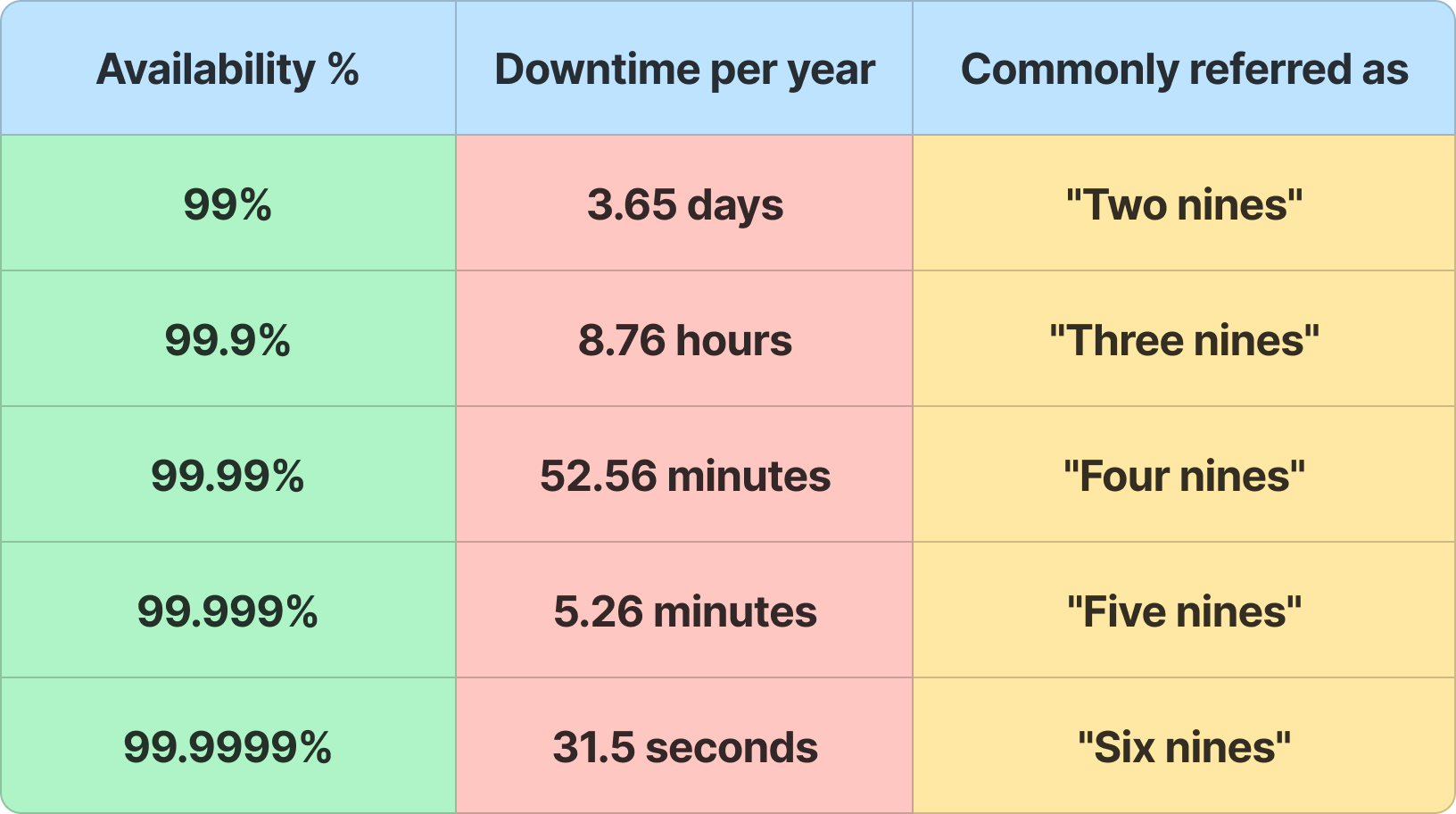
Availability is generally referred to in terms of "nines" (e.g., 99.9%, 99.99%).
Parallel Availability
- In a parallel setup, multiple components (or systems) operate independently. The system's overall availability is higher because it depends on the availability of at least one functioning component.
- If one component fails, other components can still handle the request.
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
Sequential Availability
- In a sequence setup, multiple components depend on each other. The overall system is only available if all components in the sequence are operational.
- A failure in any single component causes the entire system to fail.
Availability (Total) = Availability (Foo) * Availability (Bar)
Strategies for Improving Availability
- Redundancy
- Load Balancing
- Failover Mechanism
- The process of automatically switching to a backup system, component, or resource when a primary system fails.
- Types:
- Active-Passive Failover:
- The backup (passive) system is kept in standby mode and becomes active only when the primary system fails.
- Example: A secondary database or server that takes over when the primary one crashes.
- Active-Active Failover:
- Multiple systems (or nodes) are active and share the load simultaneously. If one fails, others continue handling the traffic.
- Example: Load-balanced web servers where all servers are active and share requests.
- Active-Passive Failover:
- Data Replication
- Monitoring and Alerts
⚖️ CAP Theorem
CAP stands for Consistency, Availability, and Partition Tolerance. The theorem states:
It is impossible for a distributed data store to simultaneously provide all three guarantees.
Consistency (C)
- Every read receives the most recent write or an error.
- All working nodes in a distributed system will return the same data at any given time.
- Crucial for applications where having the most up-to-date data is critical, such as financial systems.
Availability (A)
- Every request (read or write) receives a non-error response, without the guarantee that it contains the most recent write.
- The system is always operational and responsive, even if some nodes do not have the most up-to-date data.
- Important for systems that need to remain operational at all times, such as online retail systems.
Partition Tolerance (P)
- The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
- Partition tolerance means the system continues to function despite network partitions where nodes cannot communicate with each other.
- Essential for distributed systems because network failures can and do happen. A partition-tolerant system can maintain operations across different network segments.
Trade-Offs
-
CP (Consistency + Partition Tolerance):
- These systems prioritize consistency and can tolerate network partitions at the cost of availability. During a partition, the system may reject some requests to maintain consistency.
- Example: Traditional relational databases (MySQL, PostgreSQL) configured for strong consistency; banking systems.
-
AP (Availability + Partition Tolerance):
- These systems ensure availability and can tolerate network partitions, but at the cost of consistency. During a partition, different nodes may return different values for the same data.
- Example: Cassandra, DynamoDB; Amazon’s shopping cart designed to always accept items.
-
CA (Consistency + Availability):
- In the absence of partitions, a system can be both consistent and available. However, network partitions are inevitable in distributed systems, making this combination impractical.
- Example: Single-node databases (theoretically possible, but not practical for distributed systems).
-
In the real world, more flexible approaches are used:
- Eventual Consistency:
- For many systems, strict consistency isn't always necessary.
- Updates are propagated to all nodes eventually, but not immediately.
- Example: DNS, CDN.
- Strong Consistency:
- Ensures that once a write is confirmed, any subsequent reads will return that value.
- Tunable Consistency:
- Allows developers to configure consistency based on specific needs.
- Provides a balance between strong and eventual consistency.
- Example: Cassandra allows configuring the level of consistency on a per-query basis, providing flexibility. E-commerce platforms may require strong consistency for order processing but can tolerate eventual consistency for product recommendations.
- Eventual Consistency:
🧩 PACELC Theorem
If a partition occurs (P), a system must choose between Availability (A) and Consistency (C). Else (E), when there is no partition, the system must choose between Latency (L) and Consistency (C).