⚖️ High-Level Tradeoffs
Horizontal vs Vertical Scaling

- Horizontal scaling: buying more machines
- Vertical scaling: buying a bigger machine
HLD vs LLD
- HLD (High Level Design): How our services are going to communicate
- LLD (Low Level Design): How we are going to design classes
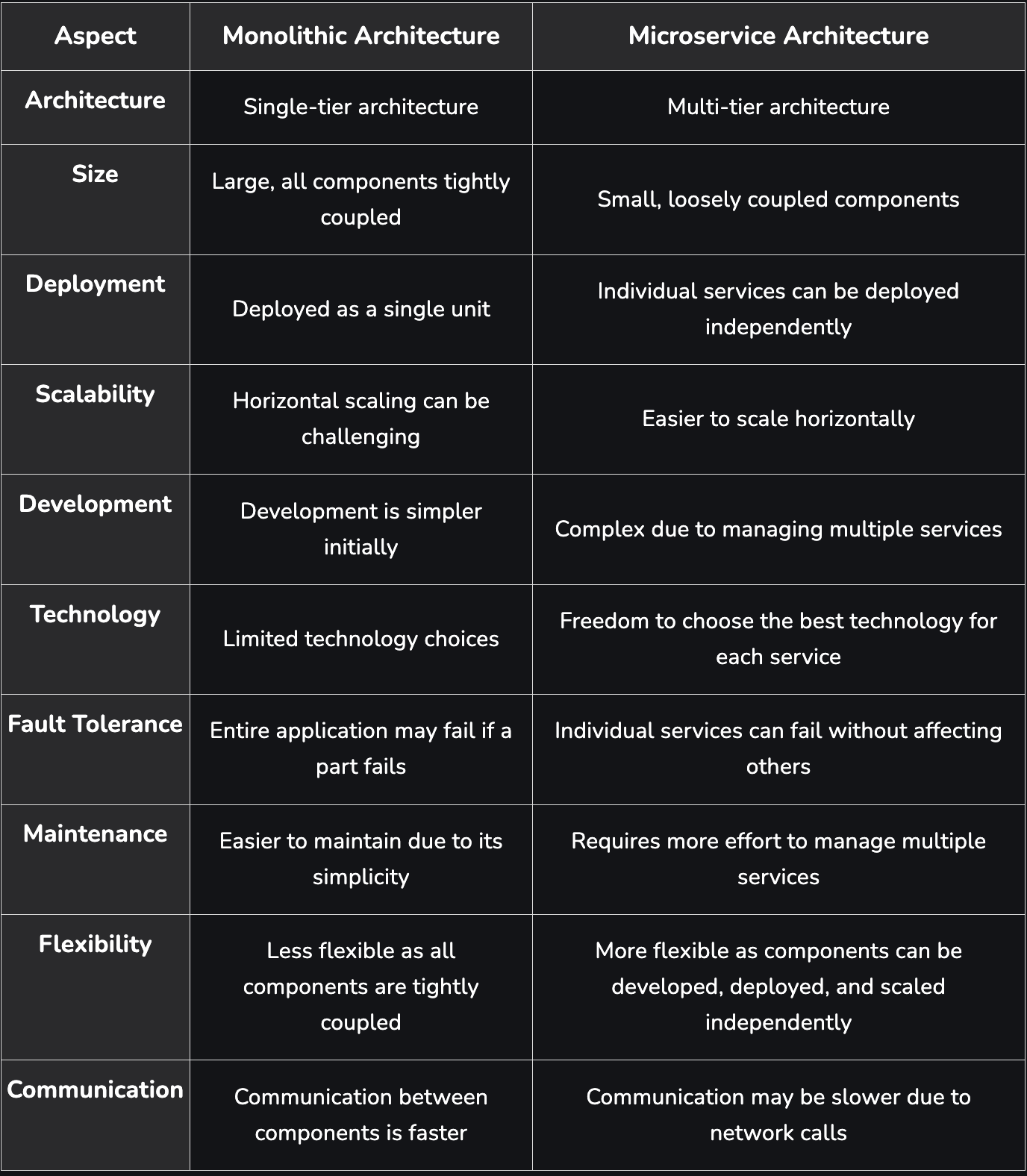
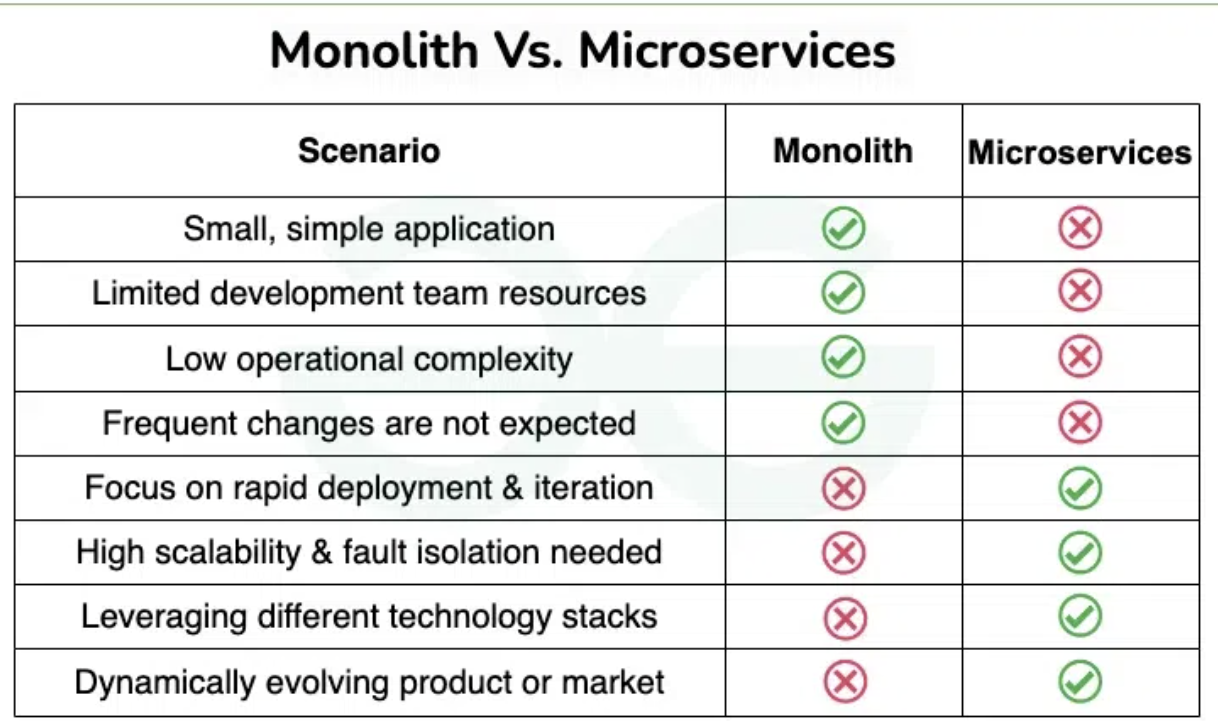
Micro services vs Monolith LINK
🚀 Performance vs. Scalability
- If you have a performance issue, your system will be slow for a single user.
- If you have a scalability issue, your system will be fast for a single user but will be slow under heavy load.
- Performance refers to how efficiently a system executes tasks under a specific workload. It focuses on response time, throughput, and resource usage.
- Scalability refers to the ability of a system to maintain performance as workload or user count increases.
⏱️ Latency vs. Throughput
- Latency is the time it takes for a single request to be processed or a task to be complete. Typically measured in milliseconds or seconds.
- Throughput refers to the rate at which a system processes requests or task. Typically measured in operations per second (ops) or transactions per second (TPS).
- Generally, we strive for maximal throughput with acceptable latency.
🟢 Availability vs. Consistency
See: Availability and Consistency
📦 Batch vs. Stream Processing
| Feature | Batch Processing | Stream Processing |
|---|---|---|
| Data Processing | Processes a large volume of data at once. | Processes data as it arrives, record by record. |
| Latency | High latency, as processing happens after data collection. | Low latency, providing near real-time insights. |
| Throughput | Can handle vast amounts of data at once. | Optimized for real-time but might handle less data volume at a given time. |
| Use Case | Ideal for historical analysis or large-scale data transformations. | Best for real-time analytics, monitoring, and alerts. |
| Complexity | Relatively simpler to implement with predefined datasets. | More complex, requires handling continuous streams. |
| Data Scope | Operates on a finite set of data. | Operates on potentially infinite streams of data. |
| Error Handling | Errors can be identified and corrected before execution. | Requires real-time handling of errors and failures. |
| Resource Usage | Resource-intensive during processing, idle otherwise. | Continuous use of resources. |
| Cost | Cost-effective for large volumes of data. | More expensive due to continuous processing. |
| Tools | Apache Hadoop, Apache Spark (Batch Mode), AWS Glue, Google Dataflow (Batch Mode) | Apache Kafka, Apache Flink, Apache Storm, AWS Kinesis, Google Dataflow (Streaming Mode) |
🗃️ Stateful vs. Stateless Design

Stateless
- Each request is treated as an independent operation.
- The server doesn't store any information about the client's state between requests.
- Advantages:
- Scalability – can add multiple servers, no need to maintain session.
- Simplicity.
- Resilience – failure on one server won't disrupt user sessions.
- Disadvantages:
- Less context for the server about the client, so personalization is not possible.
- Every request needs to carry extra data, leading to larger payloads.
- Examples:
- REST APIs
- Microservices
- CDNs
Stateful
- The system remembers client data from one request to the next.
- It maintains a record of the client's state, which can include session information, transaction details, or any other data relevant to the ongoing interaction.
- Advantages:
- Personalized experience
- Contextual continuity
- Reduced payload
- Disadv
- Scalability
- Failure prone
- Complex
- Examples
- REST APIs with session storage
- In Banking, E-commerce (cart), Multiplayer games
Concurrency vs Parallelism
Concurrency is about managing multiple tasks simultaneously, while Parallelism is about executing multiple tasks at the same time.
Concurrency

- Concurrency means an application is making progress on more than one task at the same time.
- Even on a single CPU core, This is achieved through context switching, where the CPU rapidly switches between tasks, giving the illusion of simultaneous execution.
- This seamless switching—enabled by modern CPU designs—creates the illusion of multitasking and gives the appearance of tasks running in parallel.
- The primary objective of concurrency is to maximize CPU utilization by minimizing idle time.
- Cost : Although Context switching enables concurrency but it also introduce overhead
- every switch require saving and restoring task states
- Examples
- Modern web browsers perform multiple task concurrently (like loading html/css, responding user clicks etc.)
- Used in web servers handling multiple client requests, even on a single CPU.
- Chat apps
Parallelism


- Multiple tasks are executed simultaneously.
- To achieve parallelism, an application divides its tasks into smaller, independent subtasks. These subtasks are distributed across multiple CPUs, CPU cores, GPU cores, or similar processing units, allowing them to be processed in parallel.
- Modern CPUs consist of multiple cores. Each core can independently execute a task. Parallelism divides a problem into smaller parts and assigns each part to a separate core for simultaneous processing.
- Examples
- ML training - train modesls by dividing datasets into smaller batches
- Web crawlers - breaks list of URls into smaller chunks and process in parallel
- Data processing
| Aspect | Concurrency | Parallelism |
|---|---|---|
| Execution | Achieved through context switching on a single core or thread. | Requires multiple cores or processors to execute tasks simultaneously. |
| Focus | Managing multiple tasks and maximizing resource utilization. | Splitting a single task into smaller sub-tasks for simultaneous execution. |
| Use Case | Best suited for I/O-bound tasks like handling multiple network requests or file operations. | Ideal for CPU-bound tasks like data processing or machine learning training. |
| Resource Requirement | Can be implemented on a single core or thread. | Requires multiple cores or threads. |
| Outcome | Improves responsiveness by efficiently managing task switching. | Reduces overall execution time by performing tasks simultaneously. |
| Examples | Asynchronous APIs, chat applications, or web servers handling multiple requests. | Video rendering, machine learning training, or scientific simulations. |