Databases
Relational Database
- Collection of data items organized in tables
ACID Properties
- followed by a Relational Database transaction (a transaction is a single unit of work or sometimes madeup of multiple transactions)
Atomicity
- It ensures that a transaction is treated as a single unit.
- It means either all steps of transaction complete or none of them.
- If any part of transaction fails, the transaction is rolled back and the database is restored to the previous consistent state.
- How DB handles Atomicity
- Databases unses something called logs (write ahead log) which keeps tracks of all the changes made during an transaction.
- Steps
- Transaction started
- Operations will be performed in memory
- Transaction writes all the logs
- If all steps are successful, the transaction will commit and make the changes permanent
- if any fails then rollback will be performed using the Logs
Consistency
- It means any transaction is moving databse from one consistent state to another consistent state.
- It takes care of all the constraints (uniqueness, foreign keys) to be satisfied before and after the transaction.
- If any rule fails transaction will not be committed.
- e.g. Consider a database with constraint account balance can't be negative. A transaction attempting to withdraw more money than available will fail the check so the transaction should be rolled back.
- Consistency in Distributed Systems
- Strong Consistency
- This guarantees that once a transaction is completed the latest data is available in all the nodes immediately.
- Eventual Consistency
- If a system prioritize availibility then data might take some time to be synchronize across multiple regions. Eventually all nodes will be consistent but in short term different nodes might see different version of data.
- Strong Consistency
Isolation
- It ensures that multiple transactions runs in isolation and dont effect other transaction.
- Isolation prevents data inconsistencies that can arise when 2 transactions access and update same data.
- Databases uses Locks (Shared, Exclusive) to ensure that Isolation.
- Isolation levels
- It comes with different isolation levels each having balance between performance and data integrity.
- Read Uncommited
- The lowest level where transactions can see uncomitted changes of each other
- Data corruption is high as the final value depends on the order of comm- Last one wins
- It is rarely used
- e.g. Transaction A updates
balanceto 1000 but doesn't commit yet. Transaction B can read thebalanceas 1000 eventhough it is not permanent yet.
- Read Commited
- A transaction can only read committed changes.
- It guarantees No Dirty Reads (when a transaction reads data that has been modified by another transaction, but not yet committed), and can be Non Repeatable Read (a transaction reads data, and then another transaction modifies or deletes that data before the first transaction complete.)
- Used in applications where exact consistency is less critical and performance is priority.
- e.g. TA reads
balanceas 1000 and continues and in between TB updatesbalanceto 1002 so in second read TA will read inconsistent value.
- Repeatable Read
- Once a transaction reads data, It is locked until the transaction completes.
- This guarantees no dirty reads, No Non Repeatable Reads. Phantom reads (occurs when two same queries are executed, but the rows retrieved by the two, are different, bcs new row is added or existing got deleted by some transaction) may occur.
- Serializable
- Highest level of isolation.
- Transaction executed in a serializable manner, as if they run one after another.
- This gives no Dirty reads, No Non Repeatable Reads, and no phantom reads.
Durability
-
Once a transaction is committed, its changes are permanent even in the case of a crash.
-
How it works
- This is achieved generally by writing data to a non-volatile storage (SSD, Hard drives, cloud storage) once the transaction is commited.
- Some things used here are WAL (write ahead log) and Checkpointing.
-
Master slave replication
- Only one master
- Slave only serve reads, and master server both read and write.
- Master replicates writes to slaves
- If master fails then either the DB can operate in read mode or we have to promote any slave to master or provision a new master.
- Disadvantages
- potential loss if master fails before any newly written data is written to slaves.
- Lot of write replays to slave can slow down slave.
-
Master Master replication
- Two or more servers act as master.
- Both masters serve reads and writes and coordinate with each other on writes. If either master goes down, the system can continue to operate with both reads and writes.
- Disadvantage
- All of master-slave
- need some logic to figure out where to write
- conflict resolution is time consuming
-
Federation
- Federation (Functional Partitioning) splits up the database by function. for e.g. instead of a single monolith database you can have three database : forums, users and products, resulting in less read and write traffic to each DB.
- Small database with same data can reduce cache miss as well.
- Disadvantage
- Not effective if our schema requires huge functions or tables
- Need to update application logic to determine which database to read and write.
- Joining data from two database is complex.
Sharding
SQL Tuning
- SQL tuning is the process of optimizing SQL queries and the database schema to improve the performance of a system.
- Some common ways
- Avoid expensive joins
- Use Good indices
- Partitioning, sharding in better way
Denormalization
- It helps to improve read performance at the cost of some write performance. Here some copies of data are duplicates across tables to avoid expensive joins.
- In most system reads are used more than write to increasing read performance is good.
Non-Relational Database (NoSql)
- Here Data is denormalized, and joins are generally done in the application code.
- Most NoSql Databases lacks true ACID transactions and favours eventual consistency.
- For these BASE is used to describe properties in comparison to CAP theorem.
- Basically available
- Soft state
- Eventual Consistency
Types
Key value stores
- It allows for O(1) reads.
- It allows to store metadata with a value.
- It commonly used in
Session storage,CachingandReal time data processing. - e.g. Redis, DynamoDB.
Document Store
- A document store is centered around documents (XML, JSON, binary, etc), where a document stores all information for a given object.
- It provides APIs or a query language to query based on the internal structure of documents.
- Documents are organized by collections, tags, metadata or directories.
- Useful where data model evolves over time.
- It is commonly used in
CMS,E-commerce. - e.g. MongoDB, CouchDB.
Graph Database
- They represent data as graphs, consisting of nodes (entities), edges (relationships between entities), and properties (information associated with nodes and edges).
- Commonly useful in
Social Network,Knowledge Graphs,Recommendation Systems. - e.g. Neo4j, Amazon Neptune.
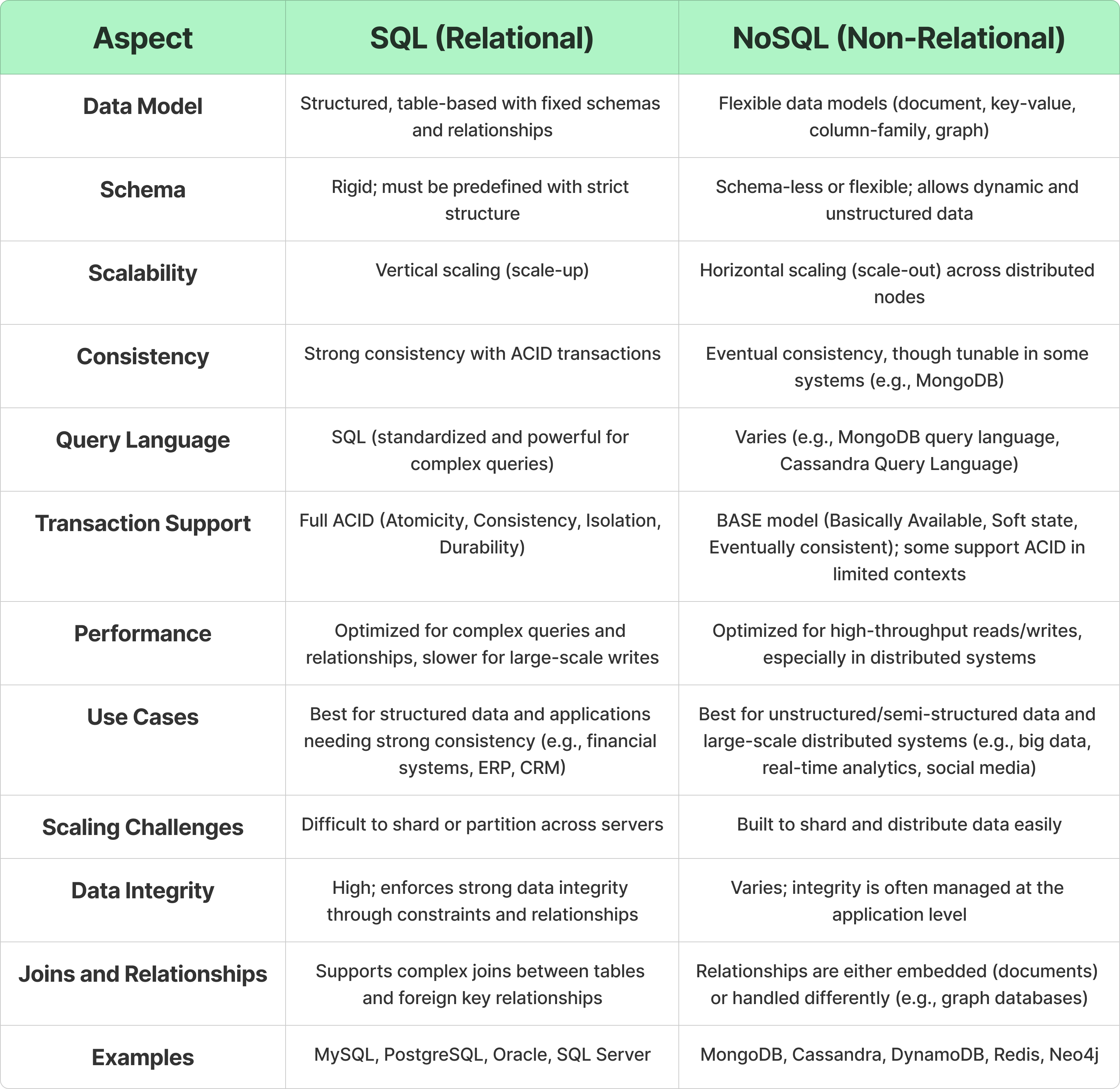
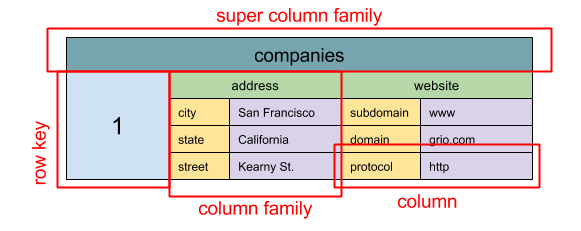
Wide Column
- A wide-column database is a type of NoSQL database in which the names and format of the columns can vary across rows, even within the same table. Wide-column databases are also known as column family databases.
- A wide column store's basic unit of data is a column (name/value pair). A column can be grouped in column families (analogous to a SQL table). Super column families further group column families. You can access each column independently with a row key, and columns with the same row key form a row. Each value contains a timestamp for versioning and for conflict resolution.
- They organize data into tables with a flexible and dynamic column structure. They are designed to handle large-scale, distributed data storage and provide high scalability and performance.
- e.g. HBase, Google Bigtable, Apache Cassandra
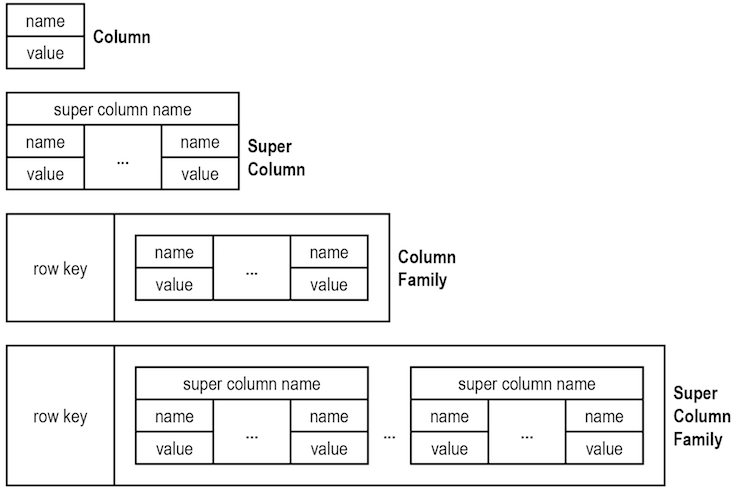
SQL vs NoSql